Recently, I started working on a mini-project called OTerminus.
The idea started from a simple question:
What if I could interact with my terminal using natural language, but without giving the language model full control over my machine?
There are already many LLM-based terminal tools out there. Some of them are powerful, some are experimental, and some are probably too risky for how I personally want to work with a terminal. My goal with OTerminus is not just to build another AI terminal. I want to use this project as a way to explore how software architecture, safety boundaries, and prompt-driven development can work together.
In other words, OTerminus is not only about asking an LLM to generate shell commands. It is about designing a controlled system where the LLM can suggest actions, but the application remains responsible for validation, policy, rendering, and execution.
That distinction matters.
The core idea
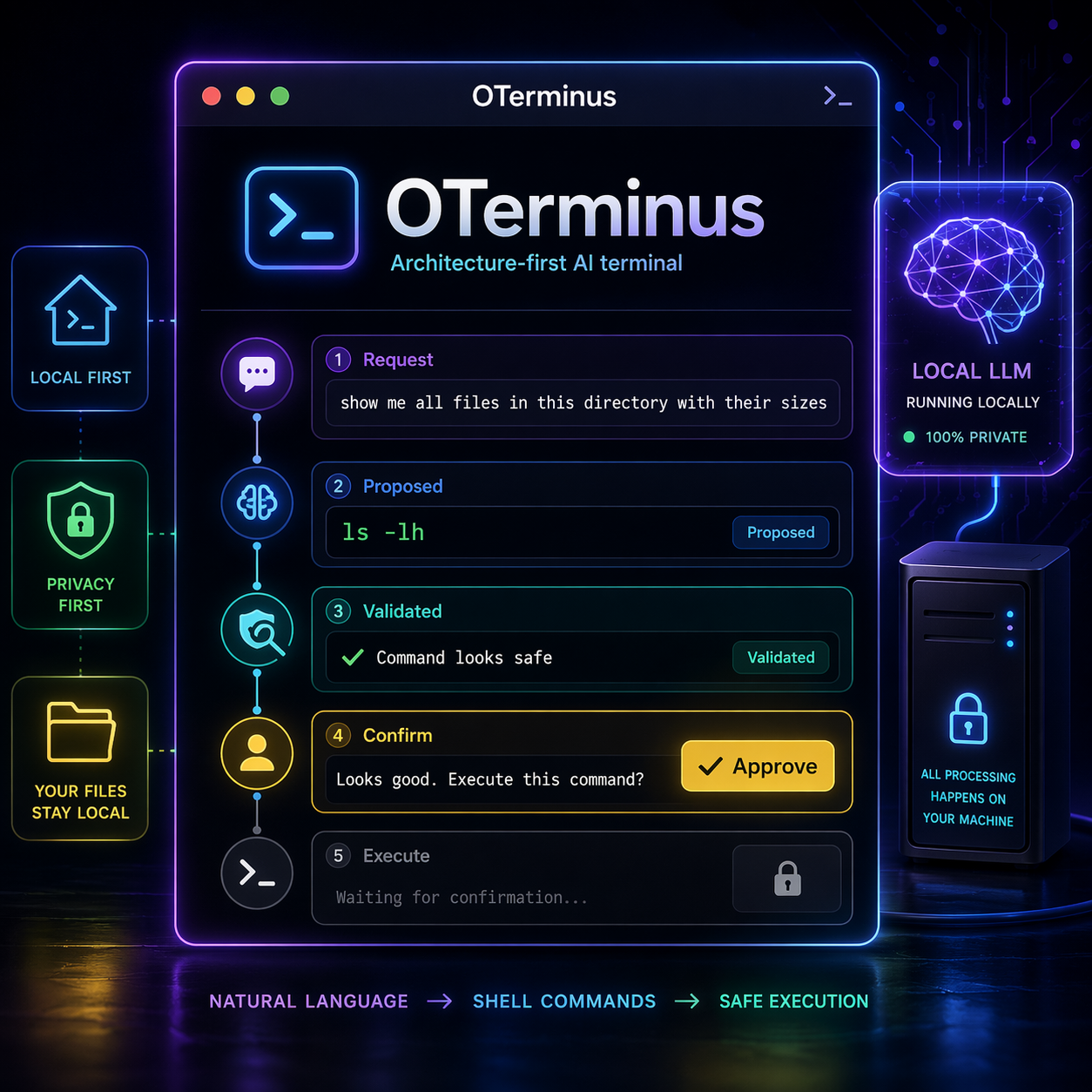
OTerminus is a local AI-powered terminal assistant. You give it a natural-language request, and it proposes a shell command. Before anything runs, the command is previewed, validated, and confirmed by the user.
For example, instead of manually writing a command, I might ask:
show me all files in this directory with their sizes
OTerminus can turn that into a proposed shell action, show me what it intends to run, explain the risk level, and ask for confirmation before execution.
The key word here is proposed.
I do not want the model to directly execute commands. I want the model to participate in planning, while the application keeps control of execution. This is especially important in a terminal environment, where a wrong command can delete files, modify permissions, expose sensitive data, or create unexpected side effects.
So the model is not the operator. It is the planner.
The Python application is the system of control.
Why local-first matters to me
At this stage, OTerminus uses Ollama so it can work with local open-source models. This gives me more flexibility while I am experimenting. I can choose the model I want, keep the workflow local, and avoid depending on a cloud provider too early.
This does not mean the project can never support cloud models. But for the current stage, I prefer the local-first approach because it fits the purpose of the project better.
A terminal assistant should be treated carefully. It sits close to the filesystem, developer environment, and sometimes sensitive project files. Starting with a local model helps me think more seriously about boundaries before adding more integrations.
The architecture: keep the LLM inside a boundary

OTerminus Infographic
The main architectural principle behind OTerminus is this:
The LLM can propose, but it should not own execution.
That principle leads to a few important design decisions.
The project separates the flow into different responsibilities:
- The CLI receives the user request.
- The system checks whether the input already looks like a direct shell command.
- If the request is natural language, the planner asks the LLM for a structured proposal.
- The proposal is parsed and validated.
- The command is rendered deterministically when possible.
- The preview is shown to the user.
- The user confirms.
- The executor runs the command.
This may sound like extra work compared to simply asking an LLM to “generate a shell command,” but this structure is exactly the point.
A terminal tool should not be designed as a loose chatbot attached to a shell. It should be designed as a controlled pipeline.
Structured proposals instead of raw shell output
One of the most important architectural choices in OTerminus is the move toward structured command proposals.
Instead of treating the LLM output as the final command, the system prefers structured data. For example, the model can return a command family like ls, find, mkdir, or grep, along with arguments that the Python layer can validate and render.
This gives the application more control.
If the model says:
{
"mode": "structured",
"command_family": "ls",
"arguments": {
"path": ".",
"long": true,
"human_readable": true
}
}
Then Python can render the actual command. The model is no longer responsible for the exact shell string. That reduces ambiguity and keeps command construction closer to deterministic application logic.
This is one of the main ideas I want to keep developing. The more the application can convert model output into structured intent, the safer and more testable the system becomes.
The command registry as a source of truth
Another important part of the design is the command registry.
The registry defines which command families are supported, how risky they are, what flags are allowed, and whether they can be detected directly. This keeps the system from becoming an open-ended shell execution engine.
For now, OTerminus supports a curated set of commands. Some are read-only inspection commands, some are write operations, and some are dangerous commands that require stricter handling.
This gives the project a clear safety model:
- Safe commands are mostly read-only.
- Write commands can modify local files.
- Dangerous commands require stronger restrictions and confirmation.
I like this approach because it makes the system explicit. The tool does not pretend that every shell command is equally safe. It classifies behavior and forces the application to treat different actions differently.
Experimental mode should be stricter, not looser
One design trap with AI tools is that “experimental” often becomes a shortcut for “allow anything.”
I want the opposite.
In OTerminus, experimental mode is meant to be explicit and stricter. If a request does not fit the structured command path, the system can still surface it as experimental, but it requires stronger confirmation and still goes through validation.
That is important because experimental capability should not silently expand the system’s authority.
If anything, experimental behavior should make the user more aware of risk.
Startup checks and model selection
I also added startup checks because the tool depends on Ollama and a local model.
Before starting, OTerminus checks whether Ollama is installed, whether it is running, and whether at least one local model is available. If no model has been configured yet, it shows the user a list of available models and asks them to choose one.
This is a small feature, but it improves the experience a lot.
A developer tool should fail clearly. If a dependency is missing, the user should not have to guess what went wrong. Good developer experience is also part of good architecture.
What I am really learning from this project
The technical side of OTerminus is interesting, but the bigger lesson for me is about how I work with AI coding tools.
I am not using Codex as a magic box where I throw vague requests and hope for good code. I am trying to use it more like a senior developer who needs clear requirements, boundaries, context, and design direction.
Before I ask Codex to implement something, I usually discuss the architecture with an AI chatbot first. I use that conversation to clarify the shape of the system, identify risks, and turn vague ideas into stronger prompts.
That extra step matters.
Vibe coding may be part of the future of programming, but I do not think it removes the need for engineering judgment. In fact, it may make engineering judgment more important. If the prompt is vague, the output will follow the vagueness. If the architecture is unclear, the implementation will drift.
The prompt becomes a steering mechanism.
The prompt structure that works for me
The structure I often use looks like this:
[General description of the task.]
Context:
[What the project does and what I want]
Goal:
[List of the goals]
Requirements:
[What the implementation must satisfy]
Design Guidance:
[Architecture direction, constraints, patterns, or boundaries]
Deliverable:
[What I expect Codex to change or produce]
This is not the only structure. It depends on the task.
If I am working on a web app, I may separate frontend, backend, database, tests, and documentation. If I am refactoring, I focus more on preserving behavior. If I am improving architecture, I describe the intended module boundaries and ask Codex not to change functionality unless required.
The point is not to follow one perfect prompt template.
The point is to give Codex enough direction so it behaves less like a random code generator and more like a developer working inside a clear technical plan.
AI as architect, Codex as developer
One way I think about my workflow is this:
I use the chatbot as a senior architect, then I use Codex as a developer.
The architect conversation helps me think through trade-offs. Should this be structured or raw? Should the validator own this responsibility? Should policy and validation be separate? Should dangerous commands be blocked by default? What should happen when the model returns invalid JSON?
Then Codex becomes more effective because the implementation request is not vague anymore.
This does not mean the AI replaces architecture. I still need to evaluate the suggestions. Sometimes I reject them. Sometimes I simplify them. Sometimes I realize that a proposed design is over-engineered for the current stage.
But the conversation helps me slow down before coding.
That is valuable.
Why architecture still matters in the age of AI coding
The easier it becomes to generate code, the easier it also becomes to generate messy systems.
That is the part I think developers should be careful about.
AI can generate files quickly. It can create modules, tests, README updates, CI workflows, and refactors. But speed does not automatically create coherence.
For a project like OTerminus, coherence matters more than speed.
The tool is dealing with shell commands. It needs boundaries. It needs predictable behavior. It needs validation. It needs a safety model. It needs tests. It needs clear separation between what the LLM proposes and what the application executes.
Without architecture, an AI terminal can easily become just a chatbot with shell access.
That is not what I want to build.
Where OTerminus can go next
OTerminus is still an early-stage personal project. There are many directions it can go.
Some future ideas include:
- richer policy packs for different environments
- better structured command coverage
- improved command explanations
- stronger audit logging
- shell-specific compatibility layers
- safer file operation abstractions
- better test coverage around risky command behavior
- more flexible model configuration
But I want to keep the same core principle:
The LLM should help the user express intent, not bypass the system’s responsibility to validate and control execution.
Final thought
OTerminus started as a small experiment, but it is becoming a useful way for me to think about AI-assisted software development.
The project itself is about building a safer AI-powered terminal. But the process is also part of the experiment.
I am learning that the quality of AI-generated code depends heavily on the quality of the thinking that happens before the prompt. Strong prompts are not just longer prompts. They are clearer prompts. They include context, goals, constraints, and architectural direction.
That is why I do not see AI coding as simply “vibe coding.”
At least for the kind of projects I want to build, the better approach is architecture-guided AI development.
Use the chatbot to think. Use Codex to implement. Keep yourself responsible for the direction.
You can find the OTerminus repository on GitHub here:
The project is still in an early stage, but I am actively using it to explore local-first AI tooling, safer terminal workflows, and architecture-guided development with Codex.